字體設計與文字編碼 Computer Typography and Character Encoding
作業 01
若該次作業有程式碼,請放在 https://github.com/你的帳號/ct2023s/hw01/src/ 檔案夾。
| 總分 | 完成後打勾 | 配分 | 分項描述 |
|---|---|---|---|
| 2 | 作業 a | ||
| 2 | 作業 b | ||
| 2 | 作業 c | ||
| 2 | 作業 d | ||
| 2 | 作業 e |
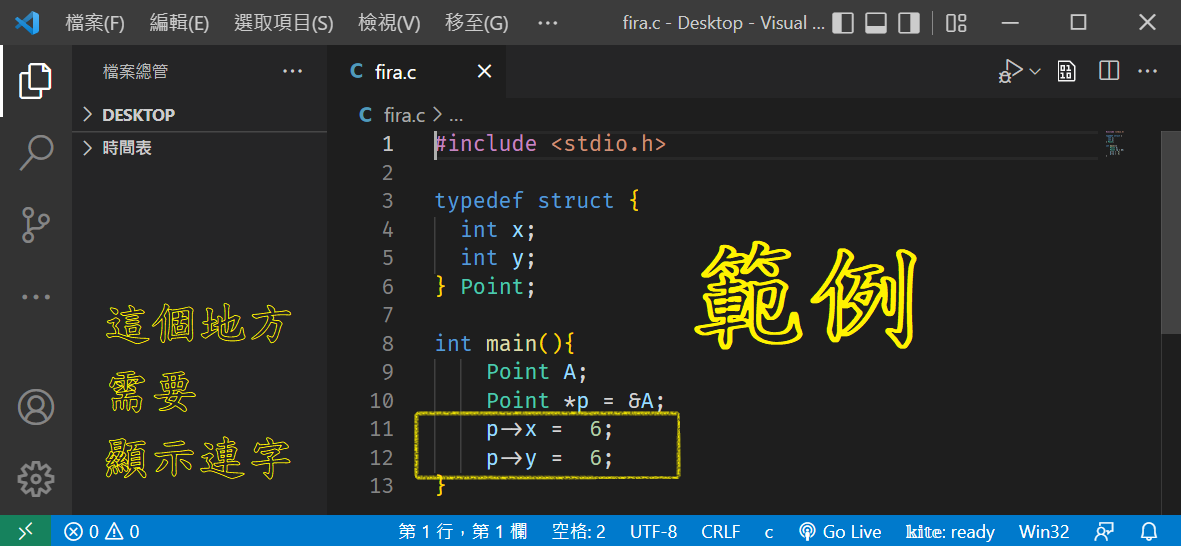
這次的內容是關於電腦上的文字編碼,在上這堂課以前,我都不知道原來電腦上的文字、表情符號等等都有不同的編碼,在Big5、UTF-8、UTF-16等等不同的編碼,顯示出來的內容也不同,甚至還有可能是亂碼,所以要用對應的編碼,不然顯示出來的不一樣就糟糕了。我覺得最酷的是e小題,雖然很常看到這類連字的文字,可是這是我第一次在電腦上看到連字,原本還以為只有人工手寫才會有這種情況呢!
「全瀨體」
- 原文出處: cjkfonts 全瀨體 https://cjkfonts.io/blog/cjkfonts_allseto
- 全瀨體,基於瀨戶字體,透過深度學習智能造字,產生的字體數量是跟思源黑體相同。
- 瀨戶字體,原作者將此字體用 SIL Open Font License 授權方法,可以商業使用,可以容許修改字體。
「FiraCode」
(a) Unicode 輸入法練習
UTF-8 encoder/decoder| 字元 | Unicode 十六進位 (Alt + x) Unicode 二進位 (按小算盤) |
BIG-5 十六進位 (中文全字庫) |
|---|---|---|
| 東 | U+6771 0110 0111 0111 0001 |
AA46 |
| 🍰 | U+1f370 0001 1111 0011 0111 0000 |
N/A |
| 姓 (君の名は) | U+59D3 0101 1001 1101 0011 |
A96D |
| 名 (君の名は) | U+540D 0101 0100 0000 1101 |
A657 |
| 名 (君の名は) | U+540D 0101 0100 0000 1101 |
A657 |
| 竜 | U+74DC 0111 0100 1101 1100 |
957C (BIG-5E) |
| 龙 | U+9F99 1001 1111 1001 1001 |
N/A |
| 龍 | U+9F8D 1001 1111 1000 1101 |
C073 |
| 龖 | U+9F96 1001 1111 1001 0110 |
N/A |
| 龘 | U+9F98 1001 1111 1001 1000 |
F9D5 |
| 𪚥 | U+2A6A5 0010 1010 0110 1010 0101 |
N/A |
(b) UTF-8 UTF-16 BE UTF-16 LE
| 字元 | Unicode | UTF-8 燕脂 | UTF-16 BE 瑠璃 | UTF-16 LE 千歳緑 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 東 | U+6771 0110 0111 0111 0001 |
E6 1110 0110 |
9D 1001 1101 |
B1 1011 0001 |
xx xxxx xxxx |
67 0110 0111 |
71 0111 0001 |
xx xxxx xxxx |
xx xxxx xxxx |
71 0111 0001 |
67 0110 0111 |
xx xxxx xxxx |
xx xxxx xxxx |
| 姓 | U+59D3 0101 1001 1101 0011 |
E5 1110 0101 |
A7 1010 0111 |
93 1001 0011 |
xx xxxx xxxx |
FE 1111 1110 |
FF 1111 1111 |
59 0101 1001 |
D3 1101 0011 |
FF 1111 1111 |
FE 1111 1110 |
D3 1101 0011 |
59 0101 1001 |
| 名 | U+540D 0101 0100 0000 1101 |
E5 1110 0101 |
90 1001 0000 |
8D 1000 1101 |
xx xxxx xxxx |
FE 1111 1110 |
FF 1111 1111 |
54 0101 0100 |
0D 1000 1101 |
FF 1111 1111 |
FE 1111 1110 |
0D 1000 1101 |
54 0101 0100 |
| 名 | U+540D 0101 0100 0000 1101 |
E5 1110 0101 |
90 1001 0000 |
8D 1000 1101 |
xx xxxx xxxx |
FE 1111 1110 |
FF 1111 1111 |
54 0101 0100 |
0D 1000 1101 |
FF 1111 1111 |
FE 1111 1110 |
0D 1000 1101 |
54 0101 0100 |
(c) 漢字中的四疊字
| 字元 | Unicode | UTF-8 燕脂 | UTF-16 BE 瑠璃 | UTF-16 LE 千歳緑 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 東 | U+6771 0110 0111 0111 0001 |
E6 1110 0110 |
9D 1001 1101 |
B1 1011 0001 |
xx xxxx xxxx |
67 0110 0111 |
71 0111 0001 |
xx xxxx xxxx |
xx xxxx xxxx |
71 0111 0001 |
67 0110 0111 |
xx xxxx xxxx |
xx xxxx xxxx |
| 𪚥 | U+2A6A5 10 1010 0110 1010 0101 |
69 0110 1001 |
D8 1101 1000 |
A5 1010 0101 |
DE 1101 1110 |
D8 1101 1000 |
69 0110 1001 |
DE 1101 1110 |
A5 1010 0101 |
F0 1111 0000 |
AA 1010 1010 |
9A 1001 1010 |
A5 1010 0101 |
| 𨰻 | U+28C3B 0010 1000 1100 0011 1011 |
F0 1111 0000 |
A8 1010 1000 |
B0 1011 0000 |
BB 1011 1011 |
D8 1101 1000 |
63 0110 0011 |
DC 1101 1100 |
3B 0011 1011 |
63 0110 0011 |
D8 1101 1000 |
3B 0011 1011 |
DC 1101 1100 |
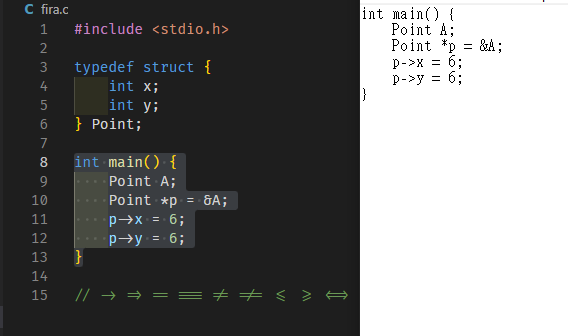
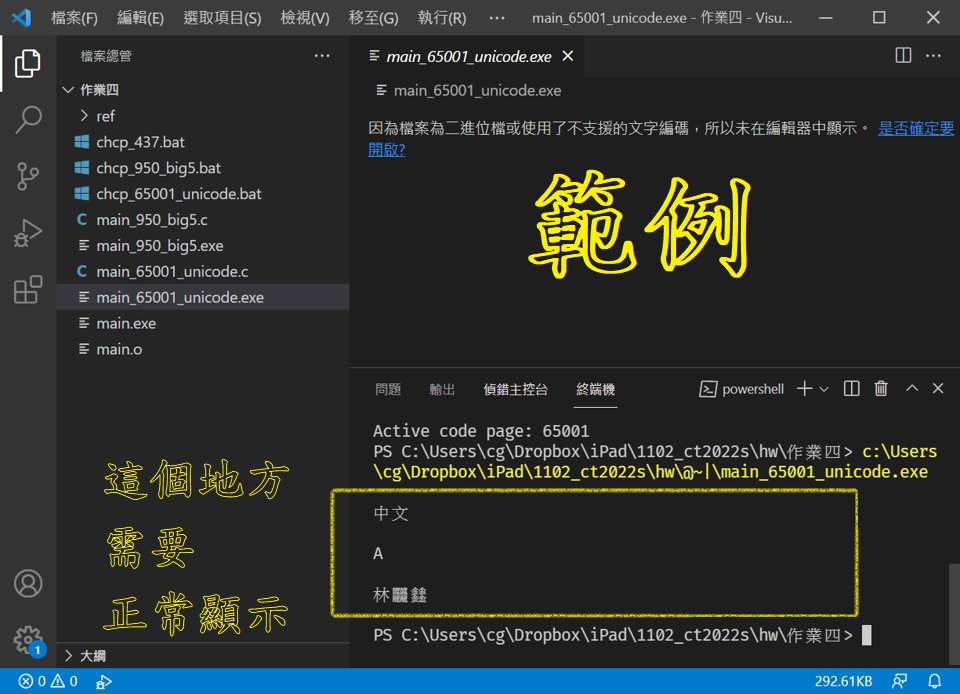
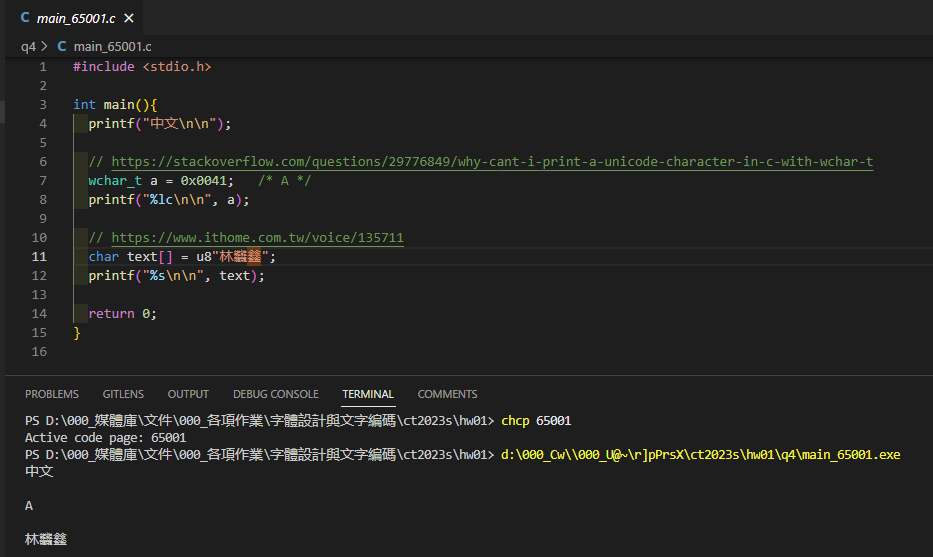
(d) 正常顯示 C 語言程式碼中的 UTF-8 漢字。
#includeint main(){ printf("中文\n\n"); // https://stackoverflow.com/questions/29776849/why-cant-i-print-a-unicode-character-in-c-with-wchar-t wchar_t a = 0x0041; /* A */ printf("%lc\n\n", a); // https://www.ithome.com.tw/voice/135711 char text[] = u8"林𪚥𨰻"; printf("%s\n\n", text); return 0; }
(e) Ligature 「合字」「連字」
FiraCode